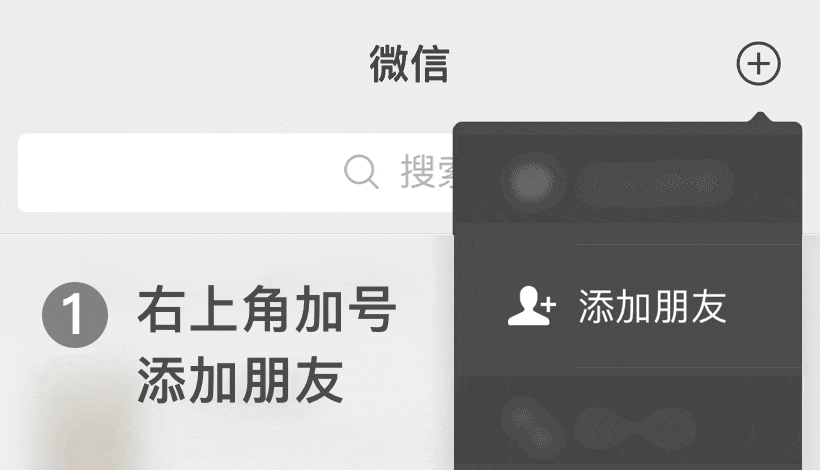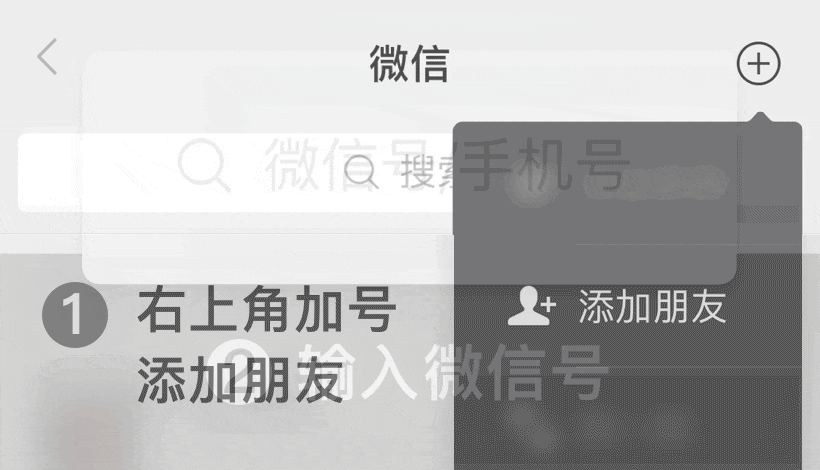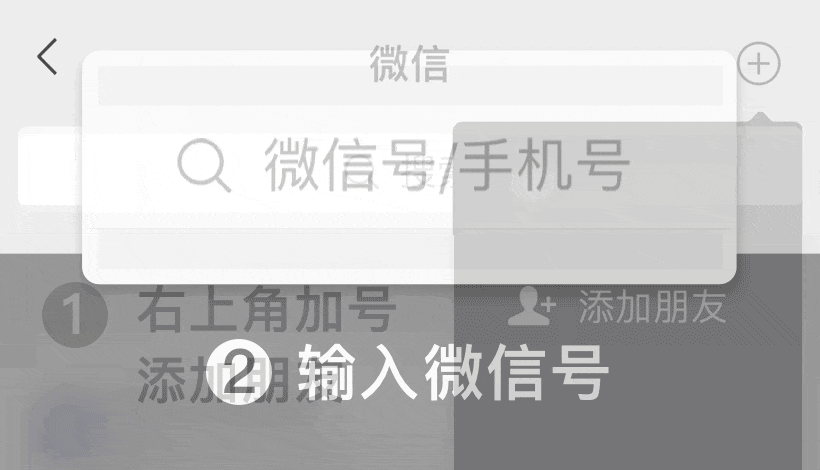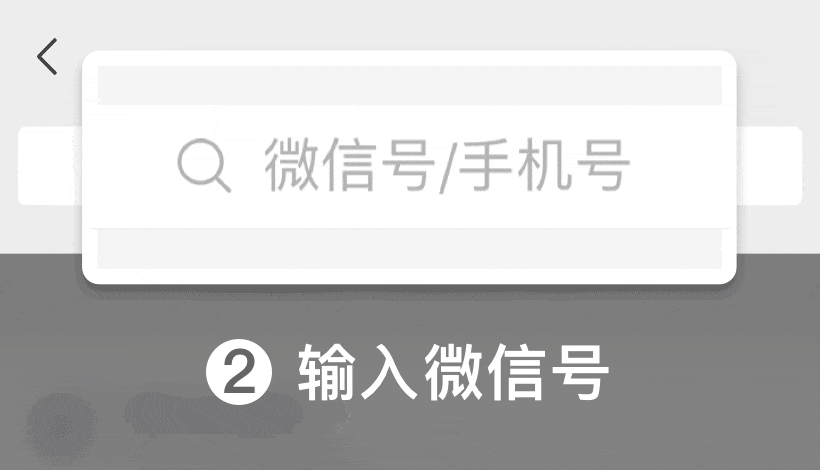
費富海360整站優(yōu)化排名軟件第2年")
費富海360一年做seo關鍵詞排名優(yōu)化")
費富海360整站優(yōu)化排名軟件第2年")
關鍵詞排名新聞
- 總結百度seo關鍵詞優(yōu)化的3大技巧
- 深圳關鍵詞優(yōu)化帶你了解外鏈形式對網(wǎng)站權重提升的作用
- 網(wǎng)站關鍵詞優(yōu)化軟件分析和論述新站內容頁面收錄延遲的原因有哪些
- 深圳關鍵詞優(yōu)化教你如何選擇優(yōu)質而穩(wěn)定的服務器
- 網(wǎng)站更換IP會不會對SEO優(yōu)化有影響
- 如何利用網(wǎng)站標題優(yōu)化獲得更多長尾關鍵詞排名
- 網(wǎng)站更換域名如何將影響降到最低
- 降低網(wǎng)站跳出率的辦法有哪些
- 關于網(wǎng)站收錄的核心問題如何解決
- 網(wǎng)站關鍵詞優(yōu)化軟件教你怎么優(yōu)化網(wǎng)站中的二級域名
- 網(wǎng)站關鍵詞優(yōu)化軟件分享關于選擇域名和空間的小技巧
- seo更新文章要注意的事項有哪些
- 關于做網(wǎng)站seo時高指數(shù)的關鍵詞該如何優(yōu)化
- 做好長尾關鍵詞是提升流量的最有效方法
- 如何分析關鍵詞優(yōu)化難度
- 深圳關鍵詞優(yōu)化軟件教你如何做好關鍵詞布局
- 網(wǎng)站關鍵詞優(yōu)化怎樣討好搜索引擎
- 分析關鍵詞排名浮動的原因有哪些
- 深圳關鍵詞優(yōu)化軟件淺談關鍵詞優(yōu)化白帽與黑帽區(qū)別
- 網(wǎng)站文章關鍵詞優(yōu)化有哪些技巧
- 如何評判網(wǎng)站關鍵詞優(yōu)化是否成功
- 深圳搜索引擎關鍵詞優(yōu)化淺談優(yōu)化網(wǎng)站的詳細方法
- 深圳關鍵詞優(yōu)化教你如何簡化標題提升關鍵詞
- 深圳關鍵詞優(yōu)化需要注意些什么
- 淺談seo優(yōu)化中有哪些常見的錯誤
百度排名優(yōu)化之Baiduspider主要抓取策略類型
其實Baiduspider在抓取過程中面對的是一個超級復雜的網(wǎng)絡環(huán)境,為了使系統(tǒng)可以抓取到盡可能多的有價值資源并保持系統(tǒng)及實際環(huán)境中頁面的一致性同時不給網(wǎng)站體驗造成壓力,會設計多種復雜的抓取策略。以下做簡單介紹:
1、抓取友好性
互聯(lián)網(wǎng)資源龐大的數(shù)量級,這就要求抓取系統(tǒng)盡可能的高效利用帶寬,在有限的硬件和帶寬資源下盡可能多的抓取到有價值資源。這就造成了另一個問題,耗費被抓網(wǎng)站的帶寬造成訪問壓力,如果程度過大將直接影響被抓網(wǎng)站的正常用戶訪問行為。因此,在抓取過程中就要進行一定的抓取壓力控制,達到既不影響網(wǎng)站的正常用戶訪問又能盡量多的抓取到有價值資源的目的。
通常情況下,最基本的是基于ip的壓力控制。這是因為如果基于域名,可能存在一個域名對多個ip(很多大網(wǎng)站)或多個域名對應同一個ip(小網(wǎng)站共享ip)的問題。實際中,往往根據(jù)ip及域名的多種條件進行壓力調配控制。同時,站長平臺也推出了壓力反饋工具,站長可以人工調配對自己網(wǎng)站的抓取壓力,這時百度spider將優(yōu)先按照站長的要求進行抓取壓力控制。
對同一個站點的抓取速度控制一般分為兩類:其一,一段時間內的抓取頻率;其二,一段時間內的抓取流量。同一站點不同的時間抓取速度也會不同,例如夜深人靜月黑風高時候抓取的可能就會快一些,也視具體站點類型而定,主要思想是錯開正常用戶訪問高峰,不斷的調整。對于不同站點,也需要不同的抓取速度。
2、常用抓取返回碼示意
簡單介紹幾種百度支持的返回碼:
1)最常見的404代表“NOT FOUND”,認為網(wǎng)頁已經(jīng)失效,通常將在庫中刪除,同時短期內如果spider再次發(fā)現(xiàn)這條url也不會抓取;
2)503代表“Service Unavailable”,認為網(wǎng)頁臨時不可訪問,通常網(wǎng)站臨時關閉,帶寬有限等會產(chǎn)生這種情況。對于網(wǎng)頁返回503狀態(tài)碼,百度spider不會把這條url直接刪除,同時短期內將會反復訪問幾次,如果網(wǎng)頁已恢復,則正常抓取;如果繼續(xù)返回503,那么這條url仍會被認為是失效鏈接,從庫中刪除。
3)403代表“Forbidden”,認為網(wǎng)頁目前禁止訪問。如果是新url,spider暫時不抓取,短期內同樣會反復訪問幾次;如果是已收錄url,不會直接刪除,短期內同樣反復訪問幾次。如果網(wǎng)頁正常訪問,則正常抓取;如果仍然禁止訪問,那么這條url也會被認為是失效鏈接,從庫中刪除。
4)301代表是“Moved Permanently”,認為網(wǎng)頁重定向至新url。當遇到站點遷移、域名更換、站點改版的情況時,我們推薦使用301返回碼,同時使用站長平臺網(wǎng)站改版工具,以減少改版對網(wǎng)站流量造成的損失。
3、多種url重定向的識別
互聯(lián)網(wǎng)中一部分網(wǎng)頁因為各種各樣的原因存在url重定向狀態(tài),為了對這部分資源正常抓取,就要求spider對url重定向進行識別判斷,同時防止作弊行為。重定向可分為三類:http 30x重定向、meta refresh重定向和js重定向。另外,百度也支持Canonical標簽,在效果上可以認為也是一種間接的重定向。
4、抓取優(yōu)先級調配
由于互聯(lián)網(wǎng)資源規(guī)模的巨大以及迅速的變化,對于搜索引擎來說全部抓取到并合理的更新保持一致性幾乎是不可能的事情,因此這就要求抓取系統(tǒng)設計一套合理的抓取優(yōu)先級調配策略。主要包括:深度優(yōu)先遍歷策略、寬度優(yōu)先遍歷策略、pr優(yōu)先策略、反鏈策略、社會化分享指導策略等等。每個策略各有優(yōu)劣,在實際情況中往往是多種策略結合使用以達到最優(yōu)的抓取效果。
5、重復url的過濾
spider在抓取過程中需要判斷一個頁面是否已經(jīng)抓取過了,如果還沒有抓取再進行抓取網(wǎng)頁的行為并放在已抓取網(wǎng)址集合中。判斷是否已經(jīng)抓取其中涉及到最核心的是快速查找并對比,同時涉及到url歸一化識別,例如一個url中包含大量無效參數(shù)而實際是同一個頁面,這將視為同一個url來對待。
6、暗網(wǎng)數(shù)據(jù)的獲取
互聯(lián)網(wǎng)中存在著大量的搜索引擎暫時無法抓取到的數(shù)據(jù),被稱為暗網(wǎng)數(shù)據(jù)。一方面,很多網(wǎng)站的大量數(shù)據(jù)是存在于網(wǎng)絡數(shù)據(jù)庫中,spider難以采用抓取網(wǎng)頁的方式獲得完整內容;另一方面,由于網(wǎng)絡環(huán)境、網(wǎng)站本身不符合規(guī)范、孤島等等問題,也會造成搜索引擎無法抓取。目前來說,對于暗網(wǎng)數(shù)據(jù)的獲取主要思路仍然是通過開放平臺采用數(shù)據(jù)提交的方式來解決,例如“百度站長平臺”“百度開放平臺”等等。
7、抓取反作弊
spider在抓取過程中往往會遇到所謂抓取黑洞或者面臨大量低質量頁面的困擾,這就要求抓取系統(tǒng)中同樣需要設計一套完善的抓取反作弊系統(tǒng)。例如分析url特征、分析頁面大小及內容、分析站點規(guī)模對應抓取規(guī)模等等。
相關產(chǎn)品





相關文章
- 百度排名優(yōu)化軟件公司講述什么是站點索引量2016年07月07日
- 百度排名優(yōu)化如何使用百度索引量工具2016年07月07日
- 百度排名優(yōu)化如何定制百度索引量查看規(guī)則2016年07月07日
- 百度排名優(yōu)化百度索引量工具常見問題2016年07月07日
- 百度排名優(yōu)化關于索引量,你必須知道的事2016年07月07日
 首頁
首頁
 添加微信
添加微信
 短信
短信
 電話咨詢
電話咨詢
 微信號:
微信號: